En l'espèce, le programme JavaScript - ci-après le programme - fera le minimum : demander au module Wasm - ci-après, le module - de calculer les couleurs des pixels de l'image constituant la représentation de l'ensemble de Mandelbrot, sur la base de paramètres décrivant cet ensemble et l'image. Autrement dit, le programme appellera une fonction exposée par le module et lui transmettra une référence sur un espace mémoire que le module remplira, et que le programme se débrouillera ensuite pour afficher.
Le point important est la manière dont le programme et le module communiquent. En premier lieu, c'est le programme qui communique un objet contenant une référence sur l'espace mémoire à peupler de pixels. La manoeuvre se déroule au moment de l'instanciation du module, via un objet ici nommé importObjectimportObject transmis en paramètre à WebAssembly.instantiate ()WebAssembly.instantiate () :
Une fois que le module est chargé, la séquence des promesses se résout par l'exécution du code utile du programme, en premier lieu l'appel à une fonction exportée par le module sous le nom de mandelbrotmandelbrot, qui calcule les couleurs des pixels de l'ensemble de Mandelbrot en fonction des paramètres qui lui parviennent. L'utilisation de response.instanceresponse.instance mentionnée plus tôt prend donc avant tout la forme suivante :
(module
(memory (import "imports" "memory") 1)
(func $mandelbrot (export "mandelbrot")
;; Calculer les pixels et les stocker dans la mémoire
)
)
- (module
- (memory (import "imports" "memory") 1)
- (func $mandelbrot (export "mandelbrot")
- ;; Calculer les pixels et les stocker dans la mémoire
- )
- )
(module
(memory (import "imports" "memory") 1)
(func $mandelbrot (export "mandelbrot")
;; Calculer les pixels et les stocker dans la mémoire
)
)
Noter que la taille initiale de la mémoire doit être définie de nouveau. Pourquoi avoir indiqué seulement une page, et non le nombre minimal de pages calculé dans le programme lors de la création de l'objet WebAssembly.MemoryWebAssembly.Memory ?
La section du
WebAssembly Reference Manual n'est pas claire sur ce point, mais la
documentation officielle ne l'est pas non plus. Une seule chose est certaine : lorsqu'une mémoire est importée, la taille initiale spécifiée dans le programme doit être supérieure ou égale à celle spécifiée dans le module. A l'inverse, que se passe-t-il si la taille initiale spécifiée dans le module est inférieure à celle spécifiée dans le programme, comme c'est le cas ici ? Pas d'explications. Un test montre que spécifier une seule page dans le module n'entrave pas les accès en écriture au-delà de cette page, tant que c'est dans la limite de la taille initiale spécifiée dans le programme. Dans ces conditions, autant se contenter de spécifier une page dans le module... Si quelqu'un trouve des précisions, qu'il me les rapporte
ici.
Le module se présente alors sous la forme d'un fichier texte, au format WebAssembly Text (
.wat). Il doit être assemblé pour produire un fichier binaire (
.wat), que le programme pourra charger. La solution la plus simple pour cela consiste à utiliser l'outil wat2wasm du
WebAssembly Binary Toolkit. Mais plutôt que de perdre du temps à l'installer, il suffit d'utiliser la version en ligne accessible
ici.
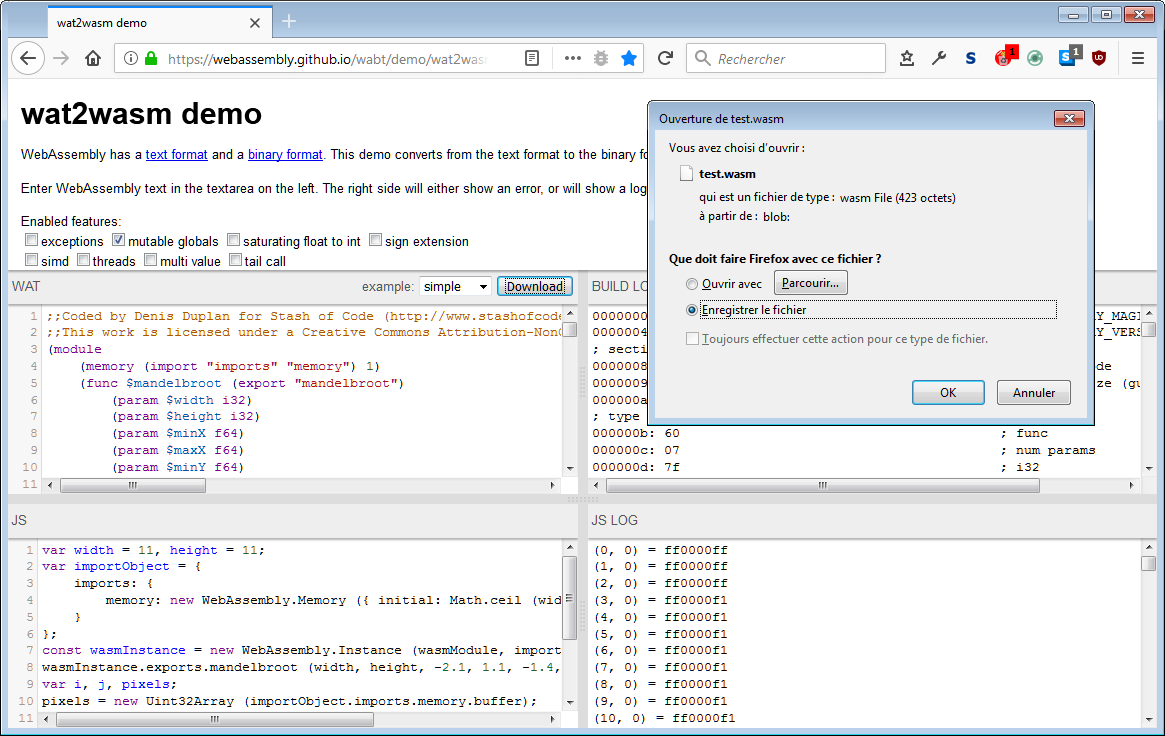
La manoeuvre consiste simplement à copier-coller le texte du module dans la fenêtre en haut à gauche, puis à cliquer sur le bouton Download pour télécharger le fichier résultant, pour l'occasion nommé mandelbrot.wasm :
Les bases de la programmation en Wasm
Le cadre étant posé, il est maintenant possible de se focaliser sur le code utile, à savoir le code du module qui doit générer les pixels, et le code du programme qui doit les afficher. Mais avant d'y venir, il faut exposer quelques principes de la programmation en Wasm à laquelle le présent article doit permettre de s'initier.
Tout n'est pas instruction... mais quoi ?
Précisons qu'il ne faut pas confondre les mots-clés utilisés pour décrire un module, tels que memory, et les instructions proprement dites du langage, tels que i32.consti32.const. Toutefois, opérer cette distinction n'est pas toujours évident. En particulier, ça ne l'est pas pour funcfunc, qui n'est pas une instruction mais un mot-clé qui entraîne formellement la création de plusieurs sections. En effet, le code suivant... :
(func)
...est assemblé sous la forme binaire suivante :
0000000: 0061 736d ; WASM_BINARY_MAGIC
0000004: 0100 0000 ; WASM_BINARY_VERSION
; section "Type" (1)
0000008: 01 ; section code
0000009: 00 ; section size (guess)
000000a: 01 ; num types
; type 0
000000b: 60 ; func
000000c: 00 ; num params
000000d: 00 ; num results
0000009: 04 ; FIXUP section size
; section "Function" (3)
000000e: 03 ; section code
000000f: 00 ; section size (guess)
0000010: 01 ; num functions
0000011: 00 ; function 0 signature index
000000f: 02 ; FIXUP section size
; section "Code" (10)
0000012: 0a ; section code
0000013: 00 ; section size (guess)
0000014: 01 ; num functions
; function body 0
0000015: 00 ; func body size (guess)
0000016: 00 ; local decl count
0000017: 0b ; end
0000015: 02 ; FIXUP func body size
0000013: 04 ; FIXUP section size
; section "name"
0000018: 00 ; section code
0000019: 00 ; section size (guess)
000001a: 04 ; string length
000001b: 6e61 6d65 name ; custom section name
000001f: 02 ; local name type
0000020: 00 ; subsection size (guess)
0000021: 01 ; num functions
0000022: 00 ; function index
0000023: 00 ; num locals
0000020: 03 ; FIXUP subsection size
0000019: 0a ; FIXUP section size
- 0000000: 0061 736d ; WASM_BINARY_MAGIC
- 0000004: 0100 0000 ; WASM_BINARY_VERSION
- ; section "Type" (1)
- 0000008: 01 ; section code
- 0000009: 00 ; section size (guess)
- 000000a: 01 ; num types
- ; type 0
- 000000b: 60 ; func
- 000000c: 00 ; num params
- 000000d: 00 ; num results
- 0000009: 04 ; FIXUP section size
- ; section "Function" (3)
- 000000e: 03 ; section code
- 000000f: 00 ; section size (guess)
- 0000010: 01 ; num functions
- 0000011: 00 ; function 0 signature index
- 000000f: 02 ; FIXUP section size
- ; section "Code" (10)
- 0000012: 0a ; section code
- 0000013: 00 ; section size (guess)
- 0000014: 01 ; num functions
- ; function body 0
- 0000015: 00 ; func body size (guess)
- 0000016: 00 ; local decl count
- 0000017: 0b ; end
- 0000015: 02 ; FIXUP func body size
- 0000013: 04 ; FIXUP section size
- ; section "name"
- 0000018: 00 ; section code
- 0000019: 00 ; section size (guess)
- 000001a: 04 ; string length
- 000001b: 6e61 6d65 name ; custom section name
- 000001f: 02 ; local name type
- 0000020: 00 ; subsection size (guess)
- 0000021: 01 ; num functions
- 0000022: 00 ; function index
- 0000023: 00 ; num locals
- 0000020: 03 ; FIXUP subsection size
- 0000019: 0a ; FIXUP section size
0000000: 0061 736d ; WASM_BINARY_MAGIC
0000004: 0100 0000 ; WASM_BINARY_VERSION
; section "Type" (1)
0000008: 01 ; section code
0000009: 00 ; section size (guess)
000000a: 01 ; num types
; type 0
000000b: 60 ; func
000000c: 00 ; num params
000000d: 00 ; num results
0000009: 04 ; FIXUP section size
; section "Function" (3)
000000e: 03 ; section code
000000f: 00 ; section size (guess)
0000010: 01 ; num functions
0000011: 00 ; function 0 signature index
000000f: 02 ; FIXUP section size
; section "Code" (10)
0000012: 0a ; section code
0000013: 00 ; section size (guess)
0000014: 01 ; num functions
; function body 0
0000015: 00 ; func body size (guess)
0000016: 00 ; local decl count
0000017: 0b ; end
0000015: 02 ; FIXUP func body size
0000013: 04 ; FIXUP section size
; section "name"
0000018: 00 ; section code
0000019: 00 ; section size (guess)
000001a: 04 ; string length
000001b: 6e61 6d65 name ; custom section name
000001f: 02 ; local name type
0000020: 00 ; subsection size (guess)
0000021: 01 ; num functions
0000022: 00 ; function index
0000023: 00 ; num locals
0000020: 03 ; FIXUP subsection size
0000019: 0a ; FIXUP section size
Comme il est possible de le constater, ce qui peut apparaître comme la définition d'une seule section dans le source du module se traduit sous la forme de plusieurs sections dans le binaire : "Function" pour la fonction, "Type" pour son type - une fonction sans argument qui ne retourne rien -, "Code" pour son corps.
Et qui utilise le code suivant... :
(func)
(func (param i32))
- (func)
- (func (param i32))
(func)
(func (param i32))
...peut constater que cela n'entraîne pas la création de nouvelles sections dans le binaire, mais la création de "sous-sections" dans ces dernières, notamment pour distinguer le type de la première fonction de celui de la seconde dans la section "Type", et pour distinguer leurs codes respectifs dans la section "Function".
funcfunc n'est donc pas une instruction ? Oui et non. Car comme cela sera expliqué plus loin, le mot-clé entraîne la définition d'une position dans le code à laquelle il est possible de sauter grâce à diverses instructions de contrôle. En ceci, funcfunc se comporte comme brbr, qui est à proprement parler une instruction...
Dans un module, le code est toujours logé dans des fonctions - en l'occurrence, il n'y en aura qu'une, qui prendra de nombreux paramètres sans retourner de résultat :
(module
(func $mandelbrot (export "mandelbrot")
(param $width i32)
(param $height i32)
;; Et autres paramètres...
;; Calculer les pixels et les stocker dans la mémoire
)
)
- (module
- (func $mandelbrot (export "mandelbrot")
- (param $width i32)
- (param $height i32)
- ;; Et autres paramètres...
- ;; Calculer les pixels et les stocker dans la mémoire
- )
- )
(module
(func $mandelbrot (export "mandelbrot")
(param $width i32)
(param $height i32)
;; Et autres paramètres...
;; Calculer les pixels et les stocker dans la mémoire
)
)
A quoi ressemble le code ? Comme précisé
ici dans la spécification, programmer en Wasm, c'est programmer une machine à pile :
WebAssembly code consists of sequences of instructions. Its computational model is based on a stack machine in that instructions manipulate values on an implicit operand stack, consuming (popping) argument values and producing or returning (pushing) result values.
Autrement dit, il n'y a pas de registres, comme par exemple en assembleur MC68000 :
move.w #100,d0 ;;Stocker 100 dans D0
move.w #10,d1 ;;Stocker 10 dans D1
sub.w d1,d0 ;;Calculer 100 - 10 et stocker 90 dans D0
- move.w #100,d0 ;;Stocker 100 dans D0
- move.w #10,d1 ;;Stocker 10 dans D1
- sub.w d1,d0 ;;Calculer 100 - 10 et stocker 90 dans D0
move.w #100,d0 ;;Stocker 100 dans D0
move.w #10,d1 ;;Stocker 10 dans D1
sub.w d1,d0 ;;Calculer 100 - 10 et stocker 90 dans D0
En Wasm, toutes les opérandes d'une instruction comme i32.subi32.sub doivent être empilées avant que l'instruction ne soit utilisée. L'instruction dépilera les opérandes, calculera la différence et empilera le résultat :
i32.const 100 ;;Empiler 100
i32.const 10 ;;Empiler 10
i32.sub ;;Dépiler 100 et 10, calculer 100 - 10, empiler 90
- i32.const 100 ;;Empiler 100
- i32.const 10 ;;Empiler 10
- i32.sub ;;Dépiler 100 et 10, calculer 100 - 10, empiler 90
i32.const 100 ;;Empiler 100
i32.const 10 ;;Empiler 10
i32.sub ;;Dépiler 100 et 10, calculer 100 - 10, empiler 90
Une notation à base de
S-expressions permet de condenser l'écriture, mais aussi de la faciliter en renversant l'ordre dans laquelle une opération est constituée. Ainsi, le code précédent peut aussi être écrit ainsi :
(i32.sub (i32.const 100) (i32.const 10))
- (i32.sub (i32.const 100) (i32.const 10))
(i32.sub (i32.const 100) (i32.const 10))
Pour une liste exhaustive des instructions de Wasm, le mieux est de se référer
ici, c'est-à-dire la partie du
WebAssembly Reference Manual consacrée aux instructions.
Le code de notre fonction $mandelbrot ()$mandelbrot () n'utilise qu'un nombre limité d'instructions. Elles manipulent deux des quatre types de valeurs possibles en Wasm : des flottants 64 bits (f64f64) et des entiers 32 bits (i32i32). La plupart de ces instructions sont assez intuitives. La liste suivante est un peu lancinante à lire, mais sa lecture permet de bien visualiser l'omniprésence des accès à la pile :
| Empile 666 sous forme d'un entier 32 bits |
| Empile 0.123 sous forme d'un flottant 64 bits |
| Dépile la valeur A dernièrement empilée (A doit être un entier 32 bits), convertit A en flottant 64 bits, empile le résultat sous fomre d'un flottant 64 bits |
| Dépile la valeur A dernièrement empilée (A doit être un flottant 64 bits), convertit sa partie entière en entier 32 bits, empile le résultat sous forme d'un entier 32 bits |
| Dépile la valeur B dernièrement empilée, puis la valeur A précédemment empilée (A et B doivent être des flottants 64 bits), additionne B à A, empile le résultat sous forme d'un flottant 64 bits |
Comme f64.addf64.add, mais avec des entiers 32 bits |
| Dépile la valeur B dernièrement empilée, puis la valeur A précédemment empilée (A et B doivent être des flottants 64 bits), soustrait B de A, empile le résultat sous forme d'un flottant 64 bits |
Comme f64.subf64.sub, mais avec des entiers 32 bits |
| Dépile la valeur B dernièrement empilée, puis la valeur A précédemment empilée (A et B doivent être des flottants 64 bits), multiplie A par B, empile le résultat sous forme d'un flottant 64 bits |
Comme f64.mulf64.mul, mais avec des entiers 32 bits |
| Dépile la valeur B dernièrement empilée, puis la valeur A précédemment empilée (A et B doivent être des flottants 64 bits), divise A par B, empile le résultat sous forme d'un flottant 64 bits |
| Dépile la valeur B dernièrement empilée, puis la valeur A précédemment empilée (A et B doivent être des entiers 32 bits), combine A avec B par OU logique bit à bit, empile le résultat sous forme d'un entier 32 bits |
| Dépile la valeur A dernièrement empilée (A doit être un entier 32 bits), teste si A est égal à l'entier 32 bits 0, empile le résultat (0 pour faux, 1 pour vrai) sous forme d'un entier 32 bits |
| Dépile la valeur B dernièrement empilée, puis la valeur A précédemment empilée (A et B doivent être des entiers 32 bits), teste si B est différent de A, empile le résultat sous forme d'un entier 32 bits (0 pour faux, 1 pour vrai) |
| Dépile la valeur B dernièrement empilée, puis la valeur A précédemment empilée (A et B doivent être des entiers 32 bits), écrit les 4 octets qui composent B à l'offset A (donné en octets !) dans l'unique mémoire autorisée |
Dépile la valeur A dernièrement empilée (A doit être du type de $x$x, déclarée par exemple une variable entière 32 bits déclarée à l'aide de (local $x i32)(local $x i32)), stocke A dans la variable locale $x$x en little endian |
Empile la valeur de la variable $x$x |
Toutefois, le code utilise aussi les instructions blockblock, looploop, brbr, et br_ifbr_if, dont le fonctionnement est nettement moins intuitif.
Comprendre les instructions de contrôle en Wasm
Les instructions de contrôle sont peu nombreuses, mais leur usage est particulièrement délicat. Comme précédemment indiqué, il ne s'agira que d'évoquer celles qui sont utilisées dans notre module, à savoir : blockblock, looploop, brbr, et br_ifbr_if. De toute manière, les autres sont bien plus faciles à comprendre.
Par ailleurs, nous n'allons pas du tout rentrer dans les détails. La manière dont ces différentes instructions fonctionnent, et tout particulièrement comment elles jouent sur la pile, est un sujet assez complexe, qui sera traité dans un prochain article. Par exemple, il s'agira de comprendre pourquoi le code suivant peut être valide... :
(func (result i32)
i32.const 7
i32.const 13
br 0
i32.const 666
)
- (func (result i32)
- i32.const 7
- i32.const 13
- br 0
- i32.const 666
- )
(func (result i32)
i32.const 7
i32.const 13
br 0
i32.const 666
)
...alors que celui-là ne l'est pas :
(func (result i32)
i32.const 7
br 0
i32.const 13
i32.const 666
)
- (func (result i32)
- i32.const 7
- br 0
- i32.const 13
- i32.const 666
- )
(func (result i32)
i32.const 7
br 0
i32.const 13
i32.const 666
)
Dans le cadre du présent article - et cela doit sonner comme un avertissement -, il ne s'agira que d'explorer des usages parfaitement balisés des instructions de contrôle mentionnées.
Comme le
WebAssembly Reference Manual permet relativement bien de le comprendre,
blockblock et
looploop, mais aussi
funcfunc qui constitue un cas particulier, servent à délimiter des parties du code, dites régions.
funcfunc doit toujours figurer dans une S-expression, ce qui permet d'en signaler la fin. Pour leur part, blockblock et looploop doivent se terminer par un endend. Par exemple :
(func
(local $i i32)
block
i32.const 7
set_local $i
end
)
- (func
- (local $i i32)
- block
- i32.const 7
- set_local $i
- end
- )
(func
(local $i i32)
block
i32.const 7
set_local $i
end
)
Toutefois, il est ici encore possible d'utiliser une S-expression pour simplifier l'écriture. En l'occurrence, cela permet de ne pas mentionner endend :
(func
(local $i i32)
(block
i32.const 7
set_local $i
)
)
- (func
- (local $i i32)
- (block
- i32.const 7
- set_local $i
- )
- )
(func
(local $i i32)
(block
i32.const 7
set_local $i
)
)
Cet exemple offre l'opportunité de lever une ambiguïté qui peut faire perdre beaucoup de temps. Le code suivant produit le même résultat :
(func
(local $i i32)
(loop
i32.const 7
set_local $i
)
)
- (func
- (local $i i32)
- (loop
- i32.const 7
- set_local $i
- )
- )
(func
(local $i i32)
(loop
i32.const 7
set_local $i
)
)
Pourquoi ? Parce que contre toute attente, looploop n'effectue pas de boucle - merci aux génies qui ont choisi de nommer l'instruction ainsi ! Dès lors, quelle différence entre blockblock et looploop ?
Pour le comprendre, il faut savoir qu'en plus de définir une région, ces instructions définissent une position dans la région - au niveau de quelle instruction dans la région, nous le verrons plus loin. Quand une position est définie, machine à pile oblige, elle est empilée. L'empilement des positions contribue à structurer le code sous la forme d'une imbrication de régions.
Depuis une région, il est possible de sauter à une autre région à l'aide de brbr ou br_ifbr_if. A cette occasion, il faut mentionner un numéro qui, partant de 0 pour désigner la région courante, est augmenté de 1 à chaque région englobante traversée : c'est la profondeur d'imbrication (nest depth), qui s'exprime donc relativement. Par exemple, si trois régions A, B et C sont successivement imbriquées :
- dans le contexte de A, la seule région accessible est 0 ;
- dans le contexte de B, les régions accessibles sont 0 (B) et 1 (A) ;
- dans le contexte de C, les régions accessibles sont 0 (C), 1 (B) et 2 (A).
Noter que le saut vers une région s'effectue alors à la position définie pour cette région - nous verrons qu'elle dépend de l'instruction utilisée pour définir la région.
Cela implique qu'il n'est donc pas possible de sauter à tout instant de n'importe quelle région, à la position de n'importe quelle autre région. Depuis une région, il est seulement possible de sauter vers cette région, ou vers une région englobante. Cela se comprend, car pour accéder à la position d'une région lors d'un branchement, il faut dépiler celles qui ont été empilées à sa suite.
Pour aller au-delà, le plus simple est de mobiliser une notation qui n'est somme toute qu'une figuration de la réalité, mais qui est assez explicite pour permettre de saisir facilement cette dernière. Aussi, il faut considérer que funcfunc définit une position à la fin de la région qu'elle définit.
Introduisons un premier branchement inconditionnel par brbr :
(func ;; Empiler (A)
(local $i i32)
(block ;; Empiler (B)
br 0 ;; Sauter en (B)
i32.const 7
set_local $i
;; (B)
)
;; (A)
)
- (func ;; Empiler (A)
- (local $i i32)
- (block ;; Empiler (B)
- br 0 ;; Sauter en (B)
- i32.const 7
- set_local $i
- ;; (B)
- )
- ;; (A)
- )
(func ;; Empiler (A)
(local $i i32)
(block ;; Empiler (B)
br 0 ;; Sauter en (B)
i32.const 7
set_local $i
;; (B)
)
;; (A)
)
Comme il est possible de le constater, la notation consiste à faire figurer explicitement dans le code, sous forme de commentaire pour ne pas bloquer l'assemblage dans wat2wasm, les positions définies par les instructions de contrôle, en comptant funcfunc parmi ces dernières.
Ainsi, br 0br 0 correspond à un branchement dans la région courante - celle de la fonction serait désignée par 11 - à la position implicitement définie à l'entrée de la région par blockblock, qui se trouve tout à la fin. Noter que funcfunc définit une position qui, elle aussi, se trouve tout à la fin de sa région.
La différence entre blockblock et looploop, c'est que looploop définit une position au début, et non à la fin, de sa région. Dans ces conditions, chacun comprendra que simplement remplacer blockblock par looploop dans le code précédent génère une boucle infinie :
(func ;; Empiler (A)
(local $i i32)
(loop ;; Empiler (B)
;; (B)
br 0 ;; Sauter en (B)
i32.const 7
set_local $i
)
;; (A)
)
- (func ;; Empiler (A)
- (local $i i32)
- (loop ;; Empiler (B)
- ;; (B)
- br 0 ;; Sauter en (B)
- i32.const 7
- set_local $i
- )
- ;; (A)
- )
(func ;; Empiler (A)
(local $i i32)
(loop ;; Empiler (B)
;; (B)
br 0 ;; Sauter en (B)
i32.const 7
set_local $i
)
;; (A)
)
S'il s'agit de réaliser une boucle avec un compteur, il est possible d'écrire :
(func ;; Empiler (A)
(local $i i32)
(set_local $i (i32.const 10))
(loop ;; Empiler (B)
;; (B)
(set_local $i (i32.sub (get_local $i) (i32.const 1)))
(br_if 0 (i32.ne (get_local $i) (i32.const 0))) ;; Sauter en (B)
)
;; (A)
)
- (func ;; Empiler (A)
- (local $i i32)
- (set_local $i (i32.const 10))
- (loop ;; Empiler (B)
- ;; (B)
- (set_local $i (i32.sub (get_local $i) (i32.const 1)))
- (br_if 0 (i32.ne (get_local $i) (i32.const 0))) ;; Sauter en (B)
- )
- ;; (A)
- )
(func ;; Empiler (A)
(local $i i32)
(set_local $i (i32.const 10))
(loop ;; Empiler (B)
;; (B)
(set_local $i (i32.sub (get_local $i) (i32.const 1)))
(br_if 0 (i32.ne (get_local $i) (i32.const 0))) ;; Sauter en (B)
)
;; (A)
)
Toutefois, selon les conditions de sortie et la manière dont elles sont écrites, il peut être nécessaire d'introduire une instruction blockblock définissant une région dans laquelle celle définit par looploop sera imbriquée. Par exemple, une boucle décrémentant de 1 deux variables, et dont il s'agirait de sortir aussitôt que l'une d'entre elles atteint 0 :
(func ;; Empiler (A)
(local $i i32)
(local $j i32)
(set_local $i (i32.const 5))
(set_local $j (i32.const 10))
(block ;; Empiler (B)
(loop ;; Empiler (C)
;; (C)
(set_local $i (i32.sub (get_local $i) (i32.const 1)))
(set_local $j (i32.sub (get_local $j) (i32.const 1)))
(br_if 1 (i32.eqz (get_local $i))) ;; Sauter en (C)
(br_if 1 (i32.eqz (get_local $j))) ;; Sauter en (C)
br 0 ;; Sauter en (B)
)
;; (B)
)
;; (A)
)
- (func ;; Empiler (A)
- (local $i i32)
- (local $j i32)
- (set_local $i (i32.const 5))
- (set_local $j (i32.const 10))
- (block ;; Empiler (B)
- (loop ;; Empiler (C)
- ;; (C)
- (set_local $i (i32.sub (get_local $i) (i32.const 1)))
- (set_local $j (i32.sub (get_local $j) (i32.const 1)))
- (br_if 1 (i32.eqz (get_local $i))) ;; Sauter en (C)
- (br_if 1 (i32.eqz (get_local $j))) ;; Sauter en (C)
- br 0 ;; Sauter en (B)
- )
- ;; (B)
- )
- ;; (A)
- )
(func ;; Empiler (A)
(local $i i32)
(local $j i32)
(set_local $i (i32.const 5))
(set_local $j (i32.const 10))
(block ;; Empiler (B)
(loop ;; Empiler (C)
;; (C)
(set_local $i (i32.sub (get_local $i) (i32.const 1)))
(set_local $j (i32.sub (get_local $j) (i32.const 1)))
(br_if 1 (i32.eqz (get_local $i))) ;; Sauter en (C)
(br_if 1 (i32.eqz (get_local $j))) ;; Sauter en (C)
br 0 ;; Sauter en (B)
)
;; (B)
)
;; (A)
)
Pourquoi cette imbrication ? Car la seule solution pour sortir de la boucle serait autrement un saut conditionnel à la région 1, c'est-à-dire à la position se trouvant à la fin de la région définie par funcfunc. Dans conditions, les éventuelles instructions se trouvant entre la fin de la boucle et la fin de la fonction ne seraient pas exécutées, ce qui ne serait vraisemblablement pas un effet recherché :
(func ;; Empiler (A)
(local $i i32)
(local $j i32)
(set_local $i (i32.const 5))
(set_local $j (i32.const 10))
(loop ;; Empiler (B)
;; (B)
(set_local $i (i32.sub (get_local $i) (i32.const 1)))
(set_local $j (i32.sub (get_local $j) (i32.const 1)))
(br_if 1 (i32.eqz (get_local $i))) ;; Sauter en (A)
(br_if 1 (i32.eqz (get_local $j))) ;; Sauter en (A)
br 0 ;; Sauter en (B)
)
nop ;; Jamais exécutée
;; (A)
)
- (func ;; Empiler (A)
- (local $i i32)
- (local $j i32)
- (set_local $i (i32.const 5))
- (set_local $j (i32.const 10))
- (loop ;; Empiler (B)
- ;; (B)
- (set_local $i (i32.sub (get_local $i) (i32.const 1)))
- (set_local $j (i32.sub (get_local $j) (i32.const 1)))
- (br_if 1 (i32.eqz (get_local $i))) ;; Sauter en (A)
- (br_if 1 (i32.eqz (get_local $j))) ;; Sauter en (A)
- br 0 ;; Sauter en (B)
- )
- nop ;; Jamais exécutée
- ;; (A)
- )
(func ;; Empiler (A)
(local $i i32)
(local $j i32)
(set_local $i (i32.const 5))
(set_local $j (i32.const 10))
(loop ;; Empiler (B)
;; (B)
(set_local $i (i32.sub (get_local $i) (i32.const 1)))
(set_local $j (i32.sub (get_local $j) (i32.const 1)))
(br_if 1 (i32.eqz (get_local $i))) ;; Sauter en (A)
(br_if 1 (i32.eqz (get_local $j))) ;; Sauter en (A)
br 0 ;; Sauter en (B)
)
nop ;; Jamais exécutée
;; (A)
)
Générer les pixels avec le module
Si vous ne connaissez pas encore la manière dont la représentation d'un ensemble de Mandelbrot peut être générée, je vous recommande de visionner cette
explication sur l'excellente chaîne YouTube
Numberphile - ça change du prof de maths barbu ! Vous y apprendrez qu'il s'agit de calculer au plus
fois
en s'interrompant prématurément dès que
. Le nombre d'itérations qu'il a fallu réaliser sert alors à déterminer l'intensité de la couleur du pixel dont les coordonnées
sont telles que
. Généralement, on pose que
correspond au point
.
La fonction mandelbrotmandelbrot exportée par le module prend plusieurs arguments :
$width$width, $height$height |
Dimensions de l'image dont il faut calculer la couleur des pixels |
$minX$minX, $maxX$maxX |
Intervalle des abscisses correspondant à la largeur de l'image |
$minY$minY, $maxY$maxY |
Intervalle des ordonnées correspondant à la hauteur de l'image |
$maxN$maxN |
Nombre maximum d'itérations |
Ce qui se traduit par le module suivant :
(module
(memory (import "imports" "memory") 1)
(func (export "mandelbrot")
(param $width i32)
(param $height i32)
(param $minX f64)
(param $maxX f64)
(param $minY f64)
(param $maxY f64)
(param $maxN i32)
;; ...
)
)
- (module
- (memory (import "imports" "memory") 1)
- (func (export "mandelbrot")
- (param $width i32)
- (param $height i32)
- (param $minX f64)
- (param $maxX f64)
- (param $minY f64)
- (param $maxY f64)
- (param $maxN i32)
- ;; ...
- )
- )
(module
(memory (import "imports" "memory") 1)
(func (export "mandelbrot")
(param $width i32)
(param $height i32)
(param $minX f64)
(param $maxX f64)
(param $minY f64)
(param $maxY f64)
(param $maxN i32)
;; ...
)
)
Maintenant que nous savons comment réaliser des boucles, le code Wasm de la fonction est assez simple à écrire. Les commentaires sont en anglais, car wat2wasm achoppe sur les caractères accentués :
(func $mandelbrot (export "mandelbrot")
(param $width i32)
(param $height i32)
(param $minX f64)
(param $maxX f64)
(param $minY f64)
(param $maxY f64)
(param $maxN i32)
(local $i i32)
(local $j i32)
(local $dx f64)
(local $dy f64)
(local $x f64)
(local $y f64)
(local $a f64)
(local $b f64)
(local $c f64)
(local $n i32)
(local $index i32)
(set_local $dx (f64.div (f64.sub (get_local $maxX) (get_local $minX)) (f64.convert_u/i32 (get_local $width))))
(set_local $dy (f64.div (f64.sub (get_local $maxY) (get_local $minY)) (f64.convert_u/i32 (get_local $height))))
(set_local $j (get_local $height))
(set_local $y (get_local $minY))
(set_local $index (i32.const 0))
(loop
(set_local $i (get_local $width))
(set_local $x (get_local $minX))
(loop
(set_local $a (f64.const 0.0))
(set_local $b (f64.const 0.0))
(set_local $n (get_local $maxN))
(block
(loop
;; $c = $a (just push it)
get_local $a
;; Set $a = $a * $a - $b * $b + $x
(f64.mul (get_local $a) (get_local $a))
(f64.sub (f64.mul (get_local $b) (get_local $b)))
(set_local $a (f64.add (get_local $x)))
;; Set $b = 2 * $c * $b + y
(f64.mul (f64.const 2.0)) ;; This pops $a
(f64.mul (get_local $b))
(set_local $b (f64.add (get_local $y)))
;; Set $n -= 1
(set_local $n (i32.sub (get_local $n) (i32.const 1)))
;; Break if $a * $a + $b * $b >= 4.0
(f64.add (f64.mul (get_local $a) (get_local $a)) (f64.mul (get_local $b) (get_local $b)))
(br_if 1 (f64.ge (f64.const 4.0)))
;; Break if $n == 0, else loop
(br_if 1 (i32.eqz (get_local $n)))
br 0
)
)
;; Store (0xFF000000 | (($n * 255 / ($maxN - 1)) & 0xFF)) at index $index
get_local $index
(i32.trunc_u/f64 (f64.div (f64.convert_u/i32 (i32.mul (get_local $n) (i32.const 255))) (f64.convert_u/i32 (i32.sub (get_local $maxN) (i32.const 1)))))
(i32.or (i32.const 0xFF000000))
i32.store
;; Same thing with S-expressions :
;;(i32.store
;; (get_local $index)
;; (i32.or
;; (i32.const 0xFF000000)
;; (i32.trunc_u/f64 (f64.div (f64.convert_u/i32 (i32.mul (get_local $n) (i32.const 255))) (f64.convert_u/i32 (i32.sub (get_local $maxN) (i32.const 1)))))
;; )
;;)
;; Set $index += 4
(set_local $index (i32.add (get_local $index) (i32.const 4)))
;; Set $x += $dx
(set_local $x (f64.add (get_local $x) (get_local $dx)))
;; Loop if $i -- != 0, else exit
(set_local $i (i32.sub (get_local $i) (i32.const 1)))
(br_if 0 (i32.ne (get_local $i) (i32.const 0)))
)
;; Set $y += $dy
(set_local $y (f64.add (get_local $y) (get_local $dy)))
;; Loop if $j -- != 0, else exit
(set_local $j (i32.sub (get_local $j) (i32.const 1)))
(br_if 0 (i32.ne (get_local $j) (i32.const 0)))
)
)
Cliquez ici pour récupérer le fichier
.wat correspondant.
La seule chose qu'il convient de commenter, c'est le stockage des pixels. Ce dernier mobilise l'instruction i32.storei32.store, qui prend deux opérandes : un indice dans la mémoire, et la valeur à stocker à cet indice dans la mémoire. La mémoire en question est implicitement la seule autorisée dans un module - en l'état actuel de WebAssembly, un module est pour l'heure limité : une mémoire au plus, une table au plus, etc. Deux remarques :
- ces opérandes doivent être empilées dans cet ordre : d'abord l'indice, puis la valeur ;
- l'indice est exprimé en octets, ce qui signifie que s'il s'agit de stocker un
i32i32 dans un tableau d'entiers codés sur 32 bits à la position $n$n, l'indice doit être 4 * $n4 * $n.
Partant, le code est le suivant :
get_local $index
(i32.trunc_u/f64 (f64.div (f64.convert_u/i32 (i32.mul (get_local $n) (i32.const 255))) (f64.convert_u/i32 (get_local $maxN))))
(i32.or (i32.const 0xFF000000))
i32.store
- get_local $index
- (i32.trunc_u/f64 (f64.div (f64.convert_u/i32 (i32.mul (get_local $n) (i32.const 255))) (f64.convert_u/i32 (get_local $maxN))))
- (i32.or (i32.const 0xFF000000))
- i32.store
get_local $index
(i32.trunc_u/f64 (f64.div (f64.convert_u/i32 (i32.mul (get_local $n) (i32.const 255))) (f64.convert_u/i32 (get_local $maxN))))
(i32.or (i32.const 0xFF000000))
i32.store
N'est-il pas possible de simplifier en utilisant plus de S-expressions ? De fait, il est parfaitement possible d'écrire :
(i32.store
(get_local $index)
(i32.or
(i32.const 0xFF000000)
(i32.trunc_u/f64 (f64.div (f64.convert_u/i32 (i32.mul (get_local $n) (i32.const 255))) (f64.convert_u/i32 (i32.sub (get_local $maxN) (i32.const 1)))))
)
)
- (i32.store
- (get_local $index)
- (i32.or
- (i32.const 0xFF000000)
- (i32.trunc_u/f64 (f64.div (f64.convert_u/i32 (i32.mul (get_local $n) (i32.const 255))) (f64.convert_u/i32 (i32.sub (get_local $maxN) (i32.const 1)))))
- )
- )
(i32.store
(get_local $index)
(i32.or
(i32.const 0xFF000000)
(i32.trunc_u/f64 (f64.div (f64.convert_u/i32 (i32.mul (get_local $n) (i32.const 255))) (f64.convert_u/i32 (i32.sub (get_local $maxN) (i32.const 1)))))
)
)
Si la forme précédente a été conservée, c'est pour illustrer le fonctionnement de i32.storei32.store étape par étape.
Afficher les pixels avec le programme
Avant d'en venir au code du programme, en voici un qui est minimaliste. Il vous permet de tester ce que le module génère dans wat2wasm, dans le cas d'une image de 11x11. Il vous suffit de le copier-coller dans la fenêtre en bas à gauche de l'outil :
var width = 11, height = 11;
var importObject = {
imports: {
memory: new WebAssembly.Memory ({ initial: Math.ceil (width * height * 4 / 65536) })
}
};
const wasmInstance = new WebAssembly.Instance (wasmModule, importObject);
wasmInstance.exports.mandelbrot (width, height, -2.1, 1.1, -1.4, 1.4, 20);
var i, j, pixels;
pixels = new Uint32Array (importObject.imports.memory.buffer);
for (j = 0; j != height; j ++) {
for (i = 0; i != width ; i++)
console.log (`(${i}, ${j}) = ${pixels[i + j * width].toString (16)}`);
}
- var width = 11, height = 11;
- var importObject = {
- imports: {
- memory: new WebAssembly.Memory ({ initial: Math.ceil (width * height * 4 / 65536) })
- }
- };
- const wasmInstance = new WebAssembly.Instance (wasmModule, importObject);
- wasmInstance.exports.mandelbrot (width, height, -2.1, 1.1, -1.4, 1.4, 20);
- var i, j, pixels;
- pixels = new Uint32Array (importObject.imports.memory.buffer);
- for (j = 0; j != height; j ++) {
- for (i = 0; i != width ; i++)
- console.log (`(${i}, ${j}) = ${pixels[i + j * width].toString (16)}`);
- }
var width = 11, height = 11;
var importObject = {
imports: {
memory: new WebAssembly.Memory ({ initial: Math.ceil (width * height * 4 / 65536) })
}
};
const wasmInstance = new WebAssembly.Instance (wasmModule, importObject);
wasmInstance.exports.mandelbrot (width, height, -2.1, 1.1, -1.4, 1.4, 20);
var i, j, pixels;
pixels = new Uint32Array (importObject.imports.memory.buffer);
for (j = 0; j != height; j ++) {
for (i = 0; i != width ; i++)
console.log (`(${i}, ${j}) = ${pixels[i + j * width].toString (16)}`);
}
Le programme que nous envisageons est plus ambitieux. Il s'agit d'afficher l'image dans une page Web à l'aide d'un canvas.
Pour ceux qui l'ignorent encore, un canvas est un objet de l'
API Canvas qui permet de manipuler une image dans une page Web. Cette API permet de dessiner des primitives de tout genre, de manière très haut-niveau par un simple appel de méthode - comme par exemple
rect ()rect () - ou un peu plus bas-niveau, en décrivant des chemins. Ce qui nous intéresse est encore plus bas-niveau : c'est la possibilité de dessiner des pixels.
D'emblée, il faut préciser que dessiner au pixel comme nous allons le faire n'est pas généralement la meilleure solution. En effet, il est bien plus rapide d'appeler la méthode
rect ()rect () pour dessiner un rectangle de 1x1 que d'écrire la séquence octets décrivant un pixel dans un
Uint32ArrayUint32Array représentant la surface. C'est a priori assez étonnant, mais cela s'explique par la manière dont la technologie fonctionne.
Cliquez ici pour tester - nous y reviendrons dans un prochain article.
Pour autant, c'est ce que nous allons faire. Rappelons l'idée de départ : balancer un paquet de données à un module et s'en faire balancer un en retour, après un traitement qui dépote. Nous ferons l'hypothèse que les performances seraient outrageusement dégradées si jamais le module devait appeler une fonction du programme à chaque pixel, et donc que le temps perdu à recopier l'ensemble des pixels générés par le module dans un tableau représentant la surface du canvas sera amplement compensé par la rapidité avec laquelle le module calculera les couleurs des pixels en question. On verra si l'hypothèse se vérifie...
Pour commencer, il faut créer le canvas. S'il est possible de simplement ajouter une balise canvascanvas dans le code HTML, procédons plutôt dynamiquement pour décortiquer le processus :
var width = 801, height = 601, canvas;
canvas = document.createElement ("canvas");
canvas.setAttribute ("width", width);
canvas.setAttribute ("height", height);
document.body.appendChild (canvas);
- var width = 801, height = 601, canvas;
- canvas = document.createElement ("canvas");
- canvas.setAttribute ("width", width);
- canvas.setAttribute ("height", height);
- document.body.appendChild (canvas);
var width = 801, height = 601, canvas;
canvas = document.createElement ("canvas");
canvas.setAttribute ("width", width);
canvas.setAttribute ("height", height);
document.body.appendChild (canvas);
Ce code crée un objet HTMLCanvasElementHTMLCanvasElement correspondant à un élément <canvas><canvas> et recupère un objet CanvasRenderingContext2DCanvasRenderingContext2D dont les propriétés et les méthodes permettent de dessiner en 2D. L'élément est alors ajouté au document.
Dès lors, il est possible d'appeler la fonction mandelbrot ()mandelbrot () exportée par le module, pour qu'elle génère autant de pixels que l'image à produire en comporte. Les paramètres concernant l'échelle de l'espace complexe correspondant et le nombre limite d'itérations ont été choisis pour des considérations esthétiques, après quelques essais :
response.instance.exports.mandelbrot (width, height, -2.1, 1.1, -1.4, 1.4, 20);
- response.instance.exports.mandelbrot (width, height, -2.1, 1.1, -1.4, 1.4, 20);
response.instance.exports.mandelbrot (width, height, -2.1, 1.1, -1.4, 1.4, 20);
Enfin, c'est le grand moment. Au retour de l'appel, l'objet WebAssembly.MemoryWebAssembly.Memory importé par le module contient les pixels. Il suffit de les recopier intégralement dans la surface de l'image. Pour cette opération, les buffers sont manipulés sous la forme optimale de tableaux d'entiers codés sur 32 bits :
inPixels = new Uint32Array (importObject.imports.memory.buffer);
context2d = canvas.getContext ("2d");
imageData = context2d.getImageData (0, 0, width, height);
outPixels = new Uint32Array (imageData.data.buffer);
outPixels.set (inPixels.slice (0, width * height - 1));
context2d.putImageData (imageData, 0, 0);
- inPixels = new Uint32Array (importObject.imports.memory.buffer);
- context2d = canvas.getContext ("2d");
- imageData = context2d.getImageData (0, 0, width, height);
- outPixels = new Uint32Array (imageData.data.buffer);
- outPixels.set (inPixels.slice (0, width * height - 1));
- context2d.putImageData (imageData, 0, 0);
inPixels = new Uint32Array (importObject.imports.memory.buffer);
context2d = canvas.getContext ("2d");
imageData = context2d.getImageData (0, 0, width, height);
outPixels = new Uint32Array (imageData.data.buffer);
outPixels.set (inPixels.slice (0, width * height - 1));
context2d.putImageData (imageData, 0, 0);
Dans ce code, la méthode Uint32Array.slice ()Uint32Array.slice () est utilisée car Uint32Array.set ()Uint32Array.set () recopie l'intégralité du tableau qui lui est fourni. Or dans notre cas, la taille de ce tableau est un multiple d'une page (64 Ko), qui a toutes les chances d'excéder le nombre de pixels width * heightwidth * height.
Attention ! Le tableau des pixels est donc un tableau d'entiers codés sur 32 bits, ce qui signifie que chaque pixels est représenté sous la forme de quatre octets. Or on n'écrit pas les octets composant un mot de 32 bits dans le même ordre en mémoire selon que la machine est en little ou big endian. Soit un pixel dont la couleur lue en une fois en mémoire sous la forme d'un mot de 32 bits doit être 0x123456780x12345678. Un PC est généralement little endian. Cela signifie que les octets composant ce mot doivent être stockés en mémoire dans cet ordre d'adresse croissante : 0x780x78 (transparence A), 0x560x56 (bleu B), 0x340x34 (vert G) et 0x120x12 (rouge R), c'est-à-dire ABGR et non RGBA. Ce serait l'inverse sur une machine big endian, typiquement un Mac doté d'un processeur PowerPC.
Tout cela pour dire que si les codes du programme et du module fonctionnent sur n'importe quel machine, choix a été fait d'adopter la logique d'une machine little endian dans le module lors de la composition de la couleur stockée en mémoire par
i32.storei32.store. A cette occasion, il a été tenu compte du fait que, comme le précise la
spécification de WebAssembly, cette instruction stocke en little endian.
L'image générée ne sera pas correcte sur une machine big endian - le rouge et la transparence seront interverties. Qui souhaite résoudre ce problème devra détecter si la machine est big ou little endian en écrivant deux octets à des adresses consécutives, puis en lisant d'un coup ces octets en lisant un mot de 16 bits : si ces octets figurent en ordre inversé dans le mot de 16 bits, la machine est little endian :
var word = new Uint8Array (2);
word[0] = 0x01;
word[1] = 0x23;
word = new Uint16Array (word.buffer);
if (word[0] == 0x0123)
// Machine big endian
else
// Machine little endian
- var word = new Uint8Array (2);
- word[0] = 0x01;
- word[1] = 0x23;
- word = new Uint16Array (word.buffer);
- if (word[0] == 0x0123)
- // Machine big endian
- else
- // Machine little endian
var word = new Uint8Array (2);
word[0] = 0x01;
word[1] = 0x23;
word = new Uint16Array (word.buffer);
if (word[0] == 0x0123)
// Machine big endian
else
// Machine little endian
Tout le code qui vient d'être présenté est à exécuter au terme de la résolution de promesses qui s'enchaînent, du chargement du fichier du binaire du module à l'instanciation de ce dernier. Ces opérations ont été présentées au début de cet article.
Cliquez ici pour tester le résultat, et récupérer par la même occasion tout le code JavaScript qui vient d'être présenté. Si vous êtes sur une machine little endian, vous devriez voir la représentation suivante de l'ensemble de Mandelbrot s'afficher :
C'est bien beau, mais ça dépote ?
Pour l'heure, ce qu'il est possible de dire, c'est que ce n'est pas bien gros ! Le fichier du binaire du module fait 420 octets, ce qui va certainement saturer notre bande passante. Toutefois, un module JavaScript équivalent minifiée à l'aide de l'
outil d'Andrew Chilton produit un fichier de 281 octets :
export default function (r,n,f,o,t,a,u){var e,i,c,d,h,v,w,y,A,M,U,b;for(e=new Uint32Array(r*n),w=(o-f)/r,y=(a-t)/n,v=t,i=0,d=0;d!=n;d++){for(h=f,c=0;c!=r;c++){for(A=0,M=0,b=u;U=A,b--,!((A=A*A-M*M+h)*A+(M=2*U*M+v)*M>=4)&&b;);e[i++]=4278190080+Math.trunc(255*b/u),h+=w}v+=y}return e}
- export default function (r,n,f,o,t,a,u){var e,i,c,d,h,v,w,y,A,M,U,b;for(e=new Uint32Array(r*n),w=(o-f)/r,y=(a-t)/n,v=t,i=0,d=0;d!=n;d++){for(h=f,c=0;c!=r;c++){for(A=0,M=0,b=u;U=A,b--,!((A=A*A-M*M+h)*A+(M=2*U*M+v)*M>=4)&&b;);e[i++]=4278190080+Math.trunc(255*b/u),h+=w}v+=y}return e}
export default function (r,n,f,o,t,a,u){var e,i,c,d,h,v,w,y,A,M,U,b;for(e=new Uint32Array(r*n),w=(o-f)/r,y=(a-t)/n,v=t,i=0,d=0;d!=n;d++){for(h=f,c=0;c!=r;c++){for(A=0,M=0,b=u;U=A,b--,!((A=A*A-M*M+h)*A+(M=2*U*M+v)*M>=4)&&b;);e[i++]=4278190080+Math.trunc(255*b/u),h+=w}v+=y}return e}
Bon, ce n'est sans doute pas d'un si petit module qu'il est possible de conclure sur l'intérêt d'économiser de l'espace. Par contre, il devrait être possible d'en tirer sur son intérêt en termes de performance.
Toutefois, la modestie du module se révèle encore une fois contraignante, car elle interdit de tirer des conclusions sur l'intérêt d'améliorer les performances durant les phases qui séparent la fin du chargement de l'exécution - ce qui est avancé comme un gros avantage sur JavaScript. Enfin, tâchons tout de même voir ce qu'il en est de la vitesse de calcul ?
Pour le savoir, une version JavaScript de la fonction mandelbrot ()mandelbrot () du module a été programmée. Afin qu'elle soit placée approximativement sur le même pied d'égalité que son homologue, elle accède à un objet Uint32ArrayUint32Array créé une fois pour toutes, tout comme le module peut accéder à un objet WebAssembly.MemoryWebAssembly.Memory créé au chargement de la page Web.
Tout bêtement, il s'agit de commander le calcul des images d'une animation qui a vocation à être jouée le plus rapidement possible, tout en restant calée sur la fréquence de rafraîchissement de l'écran. Le paramètre choisi pour faire varier la charge de calcul est le nombre maximum d'itérations, qui correspond à $maxN$maxN dans le code de notre module.
Cliquez ici pour procéder au test, qui se présente ainsi :
Même en chargeant la mule sur le petit portable utilisé pour l'occasion, aucune différence notable n'apparaît. La fonction JavaScript semble tout aussi performante que le module WebAssembly.
"Si j'aurais su, j'aurais pas venu !". Tout ça pour produire un module plus gros et pas plus rapide que le programme JavaScript équivalent ? WebAssembly, c'est donc la déception sur tous les plans. Cependant, il convient encore de rappeler que le problème choisi dans cet article n'est pas à la hauteur de la solution dont il vient de servir à tester l'efficacité. Qui recherche "webassembly performance" dans Google tombe sur des benchmarks plus sophistiqués qui peuvent laisser entendre que dans certains cas, WebAssembly peut présenter un intérêt.
Conclusion
Il faut être honnête : l'écriture du module n'a pas été des plus simples. Quand bien même wat2wasm asssemble en live le code Wasm et signale à cette occasion les erreurs de syntaxe et d'utilisation de la pile, il a fallu introduire quelques fonctions de débogage ad hoc pour bien détecter ce qui pouvait aller de travers en dépit d'une syntaxe correcte. A ma décharge, je découvrais Wasm dans un certain niveau détail à cette occasion, et je devais faire avec une documentation qui n'est pas des plus claires. En particulier, j'espère que mes explications vous éviterons de perdre du temps sur les instructions de contrôle... en attendant que je présente plus en détail comment elles fonctionnent dans un prochain article.
Est-il intéressant de s'intéresser à WebAssembly ? Comme toujours en matière d'innovation technologique : oui, mais prudemment. A ce jour, comme le précise
Can I use?, cette technologie a été adoptée par les principaux navigateurs. Toutefois, force est de constater que les réalisations sont rares : d'une recherche portant sur "webassembly demo" sur Google, il ne ressort pas grand-chose. Par ailleurs, la plus-value en termes de performance reste à démontrer, mais il est vrai qu'il ne faut pas se limiter à cette question, les objectifs de WebAssembly rappelés
ici étant bien plus généraux.
WebAssembly n'en est qu'à ses débuts ; ceux qui sont en charge de l'implémentation de WebAssembly sur les navigateurs sont encore à la tâche. Ainsi qu'en témoigne
cette liste, les fonctionnalités dont il est question d'enrichir la technologie sont nombreuses, allant de la possibilité de charger un module comme n'importe quel module JavaScript, à celle pour une fonction de retourner plusieurs valeurs, en passant par celle de manipuler directement le DOM - et plus généralement d'accéder aux diverses API - dans le contexte d'une page Web.
Bref, regarder pour savoir de quoi il en retourne, et s'amuser un peu. Pour le reste, attendre et voir.
Réinventer le CPU dans le contexte du navigateur : la fin de JavaScript ?
Comme j'ai déjà eu l'occasion de le faire remarquer
ici, le Web a constitué pour les développeurs une régression incroyable. Le fait est qu'il a fallu tout simplement réinventer la roue pour la faire tourner dans une architecture
Representational State Transfer (REST). En 2018, nous en sommes encore à essayer de revenir au niveau de confort qu'offrait la programmation avant le Web, en réinventant des concepts aussi élémentaires que la compilation et la liaison. La seule différence, c'est que nous nous "aidons" en cela de
toolchains horriblement complexes à base de
npm,
webpack et autres, qu'il n'est possible d'utiliser simplement que dans des IDE extrêmement lourds.
Bien évidemment, il faut voir les bons côtés de la chose. Les apports de l'architecture REST sont considérables. La connectivité généralisée qu'elle a permis d'établir avec le Web sert à la fois de support et de moyen pour des innovations sidérantes. Citer npm comme à l'instant, ce sera pour critiquer le fait que c'est un outil en ligne de commandes qui entraîne la création d'un myriade de fichier à la moindre installation d'un package - un vrai gaspillage de bande passante et d'espace disque -, mais certainement pas pour critiquer le fait que l'outil donne accès à d'innombrables packages produits par la Terre entière, une sorte de
bibliothèque d'Alexandrie.
Tout de même, dans le domaine du développement, nous sommes loin, très loin, d'avoir atteint le niveau de maturité qui permettrait de tirer pleinement parti de REST.
Pour revenir à WebAssembly, si l'on prend du recul sur l'évolution de cette technologie du Web que constitue le navigateur, on constate que la tendance a depuis toujours été d'en faire un OS dans l'OS. Avec WebAssembly, on passe à un autre niveau qui consiste à faire du navigateur une machine dans la machine. Ce projet est ancien : c'est celui de la machine virtuelle. Toutefois, il n'était pas jusqu'à ce jour question de pouvoir écrire du bytecode à la main, ou d'en générer à partir de n'importe quel langage, car il n'existait pas de langage intermédiaire pour cela. C'est l'innovation qu'introduit WebAssembly. On en est donc là dans le retour en arrière : on se met à programmer en assembleur dans le contexte d'un navigateur comme on programmait un CPU de base avant le Web. Inévitablement, les évolutions à venir de WebAssembly tiendront plus du recyclage que de l'innovation.
Il n'en reste pas moins que WebAssembly a tout le potentiel pour bouleverser l'écosystème du développement front-end pour le Web, tout particulièrement en réduisant drastiquement ce qu'il sera encore nécessaire de programmer en JavaScript. Qu'on y songe : à compter du moment où un module WebAssembly pourra aussi bien dialoguer avec l'environnement d'exécution du navigateur comme c'est un des objectifs rappelé
ici, et qu'il sera possible de compiler un source écrit dans un langage quelconque pour produire un tel module, JavaScript ne sera certainement plus aussi incontournable qu'il ne l'est aujourd'hui. Mais pour que tout bascule, il faudra une démonstration incontestable du gain en productivité que représente la généralisation du recours à WebAssembly.
Pour en savoir plus...
Pour ceux qui ne connaîtraient pas encore, ou qui sentent qu'ils ne connaissent somme toute pas bien Node.js, je signale cette excellente
présentation par Mosh Hamedani. Une heure de votre temps que vous ne perdrez pas !