Pour la Saint Valentin 2021, l'U.S. Cyber Command propose dans un tweet de résoudre une douzaine de puzzles de cryptographie. Cliquez ici pour les récupérer. Une excellente initiative qui suscitera peut-être des vocations...
Pourquoi ne pas s'y essayer ? Nous verrons bien où cela nous mène... Je publierai sur ce site les solutions auxquelles je serai parvenu, sous la forme des notes prises chemin faisant, rendant donc compte d'éventuels errements, ce qui sera plus vivant.
Aujourd'hui, la solution du puzzle 9.

Il y a deux images : un dessin et un tableau qui associe des emojis à des caractères, présenté comme la clé.
Le dessin représente un chien tenant un coeur, avec des lunettes qui filtrent les couleurs sauf le rouge. Cela devrait me mettre sur la piste de l'extraction de la composante R, ou du moins de son LSB, mais s'agissant d'un PNG, en vieux routier de la stéganographie, je vérifie tout suite si des données ne figurent pas après le chunk IEND. Pour cela, je n'utilise même pas pngcheck, mais directement HxD.
Bien m'en prend, car je trouve 57 500 octets superflus après la fin réglementaire du PNG. Je les claque dans un fichier step0.bin. C'est une série de séquences commençant visiblement toutes par f0 :
f0 9f 92 98 f0 9f 98 89 e2 99 a5 f0 9f 92 9d f0 9f a5 b0 e2 9d a3 f0 9f 98 87 f0 9f 91 a8 ...
Le tableau fait correspondre des emojis et des caractères. Ces séquences seraient les codes d'emojis ? De fait, en cherchant "f0 9f 92 98" sur Google, je tombe sur une table de caractères, dont tous les emojis.
Je me livre alors à un travail bien chiant : retrouver le code de chaque emoji de la clé... Pour m'aider, je trouve une autre table, qui dispose pour sa part d'un moteur de recherche. Le problème, c'est que contrairement à la première, elle ne fournit pas le code d'un emoji sous la forme UTF-8, c'est-à-dire une séquence d'octets, mais simplement sous la forme "U+...". Bah ! J'utilise son moteur de recherche pour trouver un emoji à partir de ce qu'il m'inspire, et une fois que je l'ai trouvé, je m'aide de son code "U+..." pour le retrouver dans la première table, et donc tomber sur son code UTF-8.
Ce n'est pas toujours facile, car j'ai des hésitations. Par exemple, le petit coeur rouge qui correspond à "s" dans la clé, je le trouve dans la seconde table il me semble, mais c'est un petit coeur noir dans la première, et son code UTF-8 a une forme différente des autres : e2 99 a5, soit 3 octets et non 4. Pour avancer, je m'appuie sur deux choses :
- Un relevé d'erreurs d'un programme que je code en Python, pour identifier les séquences hexadécimales que j'aurais loupées. Bref, toutes les séquences figurant dans la fin du fichier PNG sont-elles bien identifiées ?
- Une comparaison des emojis figurant dans la clé avec les emojis produits par Word interprétant un fichier binaire contenant toutes les séquences hexadécimales que j'ai identifiées, pour vérifier l'exactitude de ces dernières. Bref, les icônes dans Word sont-elles bien celles de la clé ?
- keys = {
- b'\xf0\x9f\x98\x81': 'x',
- b'\xf0\x9f\x8d\xab': 'm',
- b'\xf0\x9f\x98\x8a': '5',
- b'\xf0\x9f\xa7\x91': 'b',
- b'\xf0\x9f\x92\x9e': 'M',
- b'\xf0\x9f\x98\x80': 'u',
- b'\xe2\x9d\xa3': 'P',
- b'\xf0\x9f\x91\xab': 'd',
- b'\xf0\x9f\x98\x8d': 'B',
- b'\xf0\x9f\x98\x83': 'v',
- b'\xf0\x9f\x92\x93': 'L',
- b'\xf0\x9f\x92\x9b': 'T',
- b'\xf0\x9f\x92\x8f': 'f',
- b'\xf0\x9f\xa4\x8d': 'Z',
- b'\xf0\x9f\x98\x98': 'C',
- b'\xf0\x9f\x8c\xb9': 'k',
- b'\xf0\x9f\x8f\xa9': 'n',
- b'\xf0\x9f\x92\x97': 'K',
- b'\xf0\x9f\x92\x8b': 'F',
- b'\xf0\x9f\x98\x86': 'y',
- b'\xf0\x9f\x91\xad': 'c',
- b'\xf0\x9f\xa5\xb0': 'A',
- b'\xf0\x9f\xa4\x9f': 'a',
- b'\xf0\x9f\x91\xa8': 'h',
- b'\xf0\x9f\x91\xac': 'e',
- b'\xf0\x9f\xa7\xa1': 'S',
- b'\xf0\x9f\x98\x9b': '/',
- b'\xf0\x9f\x92\x95': 'N',
- b'\xf0\x9f\x92\x8d': 't',
- b'\xf0\x9f\x8e\x80': 'p',
- b'\xf0\x9f\x92\x91': 'i',
- b'\xf0\x9f\xa4\x8e': 'X',
- b'\xf0\x9f\x92\x98': 'H',
- b'\xf0\x9f\x98\x8b': '+',
- b'\xf0\x9f\x92\x9a': 'U',
- b'\xf0\x9f\x98\x85': 'z',
- b'\xf0\x9f\xa7\xb8': 'r',
- b'\xf0\x9f\x8e\x81': 'q',
- b'\xf0\x9f\x92\x90': 'j',
- b'\xf0\x9f\x96\xa4': 'Y',
- b'\xf0\x9f\x92\x99': 'V',
- b'\xf0\x9f\x99\x83': '3',
- b'\xf0\x9f\x92\x8c': 'G',
- b'\xf0\x9f\x98\xbb': 'E',
- b'\xf0\x9f\xa4\xa3': '0',
- b'\xf0\x9f\x98\x89': '4',
- b'\xf0\x9f\x91\xa9': 'g',
- b'\xf0\x9f\xa4\xa9': '7',
- b'\xf0\x9f\x92\x9c': 'W',
- b'\xe2\x99\xa5': 's',
- b'\xf0\x9f\x94\xa5': 'o',
- b'\xf0\x9f\xa5\x80': 'l',
- b'\xe2\x9d\xa4': 'R',
- b'\xf0\x9f\x92\x9d': 'I',
- b'\xf0\x9f\x99\x82': '2',
- b'\xf0\x9f\x92\x94': 'Q',
- b'\xf0\x9f\x98\x87': '6',
- b'\xf0\x9f\x98\x9a': 'D',
- b'\xf0\x9f\x98\x82': '1',
- b'\xf0\x9f\x98\x99': '9',
- b'\xf0\x9f\x98\x97': '8',
- b'\xf0\x9f\x92\x9f': 'O',
- b'\xf0\x9f\x98\x84': 'w',
- b'\xf0\x9f\x92\x96': 'J'
- }
- f = open (f'{path}step0.bin', 'rb')
- data = f.read ()
- f.close ()
- s = ''
- i = 0
- while i < len (data):
- if data[i] == 0xf0:
- n = 4
- else:
- n = 3
- found = False
- for k in keys:
- if data[i:i + n] == k:
- s += keys[k]
- found = True
- break
- if found == False:
- print (':'.join([hex(b)[2:] for b in data[i:i + 4]]) + ' not found')
- i += n
Cela me prend pas mal de temps... La traduction par le programme Python précédent débouche sur du base64 que je stocke dans un fichier step1.b64. Toujours en Python, je le décode, ce qui me donne un binaire que j'engrange dans un fichier step2.bin :
- import base64
- while len (s) % 4 != 0:
- s += '='
- file = open (f'{path}step1.b64', 'wt')
- file.write (s)
- file.close ()
- data = base64.b64decode (s.encode ('utf-8'))
- file = open (f'{path}step2.gz', 'wb')
- file.write (data)
- file.close ()
Dans HxD, ce binaire ne ressemble à rien. Je passe le fichier sur ma machine virtuelle Kali Linux tournant sous Hyper-V pour tester avec quelques outils. TrID ne dit qu'il s'agit de données compressées en GZ / GZIP, et binwalk, qui est quand même bien plus fiable, me dit qu'il s'agit de données compressées en gzip.
En conséquence, je renomme le fichier en flag.gz, et je tente de le désarchiver, mais gunzip ne le reconnaît pas.
Ne serait-ce pas une section IDAT ? Je retourne dans Python pour voir si je peux dézipper ce binaire. Pour cela, je ressors du code que j'avais écrit pour un challenge de stéganographie sur Root Me, afin de rechercher des sections débutant par un header zlib et tenter de les décompresser. Bilan, il trouve deux headers, mais ne parvient pas à décompresser...
Là, je galère. Je décide de travailler sur d'autres puzzles en attenant d'avoir une idée géniale, car quand c'est comme ça, une douloureuse expérience m'a appris qu'il vaut mieux ne pas insister.
Un ou deux jours après, je reviens sur ce puzzle. Tout de même, ouvert dans 7-Zip, le binaire résultant du décodage de step1.b64 apparaît un peu reconnu, laissant entendre que c'est l'archive d'un fichier de 1 904 898 octets. Mais la décompression plante. Or en testant avec un fichier qui n'en est rien un GZIP, je vois que 7-Zip ne va pas aussi loin. Bref, c'est peut-être malgré tout la bonne piste ?
A tout hasard, je tente d'utiliser gzrt, un outil qui prétendd réparer les GZIP abîmés. Malheureusement, ce qu'il me sort ne ressemble à rien.
Du coup, je cherche à voir où j'ai une erreur dans step2.bin. Je compare ce que je vois dans HxD au début du fichier, et la description du header dans la spécification du format GZ. Le header semble correct :
1f:8b Magic number OK 08 Compression method Deflate OK 00 File flags OK car à 0x00 ? fe:a1:24:60 32-bit timestamp OK car 2021-02-11T04:18:22 02 Compression flags ? ff Operating system ID OK car unknown ?
Le fichier se termine par un CRC de 32 bits, suivi d'une taille du fichier décompressé sur 32 bits. Ici :
11 f9 a7 5e 02 11 1d 00 1 904 898 octets
A ce stade, j'ai la conviction que c'est bien un fichier GZIP, mais que quelque chose doit déconner dans le base64 d'où je l'ai sorti, donc dans le résultat de ma conversion des emojis.
Comme j'en ai marre, je ne me pose pas de question. J'ouvre step0.bin dans Word, et je remplace à la main chaque emoji par son caractère d'après la clé. C'est super-chiant, mais cela me permet de récupèrer un base64 qui me donne un GZIP que je peux décompresser !
Sauf que le résultat est un autre GZIP, dont la décompression plante... J'ai dû me planter quelque part, encore une fois.
Finalement, en comparant le base64 produit par mon programme Python et celui produit par mes rechercher-remplacer dans Word, je trouve des erreurs dans ma table de conversion. Je corrige dans Python...
Ouf ! le fichier base64 produit un GZIP valide, dont la décompression donne un fichier que je nomme step3.bin de 1 905 090 octets.
- import gzip
- data = gzip.decompress (data)
- file = open (f'{path}step3.bin', 'wb')
- file.write (data)
- file.close ()
Kézako, ce fichier ? TrID ne reconnaît pas le type de fichier - mais je ne sais pas pourquoi je m'obstine encore à utiliser cet outil, tellement c'est une merde. Je regarde dans HxD : encore des codes UTF-8 d'emojis...
Du coup, je charge le fichier dans Word, ce qui me permet de constater que ce sont des lignes de coeurs noirs ou blancs :

Il est évident que c'est la codification d'une image de pixels noirs et blancs. Vite fait, je programme en Python de quoi générer un PNG à partir de cela :
- file = open (f'{path}step3.bin', 'wb')
- file.write (data)
- file.close ()
- pixels = []
- row = []
- pixels.append (row)
- for b in data:
- if b == 0x0a:
- row = []
- pixels.append (row)
- elif b == 0x8d:
- row.append (0)
- elif b == 0x96:
- row.append (1)
- height = len (pixels) - 1
- width = len (pixels[0])
- from PIL import Image, ImageDraw
- image = Image.new ('RGB', (width, height), (255, 255, 255))
- for y in range (height):
- for x in range (width):
- if pixels[y][x] == 1:
- image.putpixel ((x, y), (0, 0, 0))
- image.save (f'{path}step4.png')
Je dépose le résultat dans un fichier step4.png :

C'est donc un gros QR Code de 690 x 690 pixels. Je le décode sur ZXing :
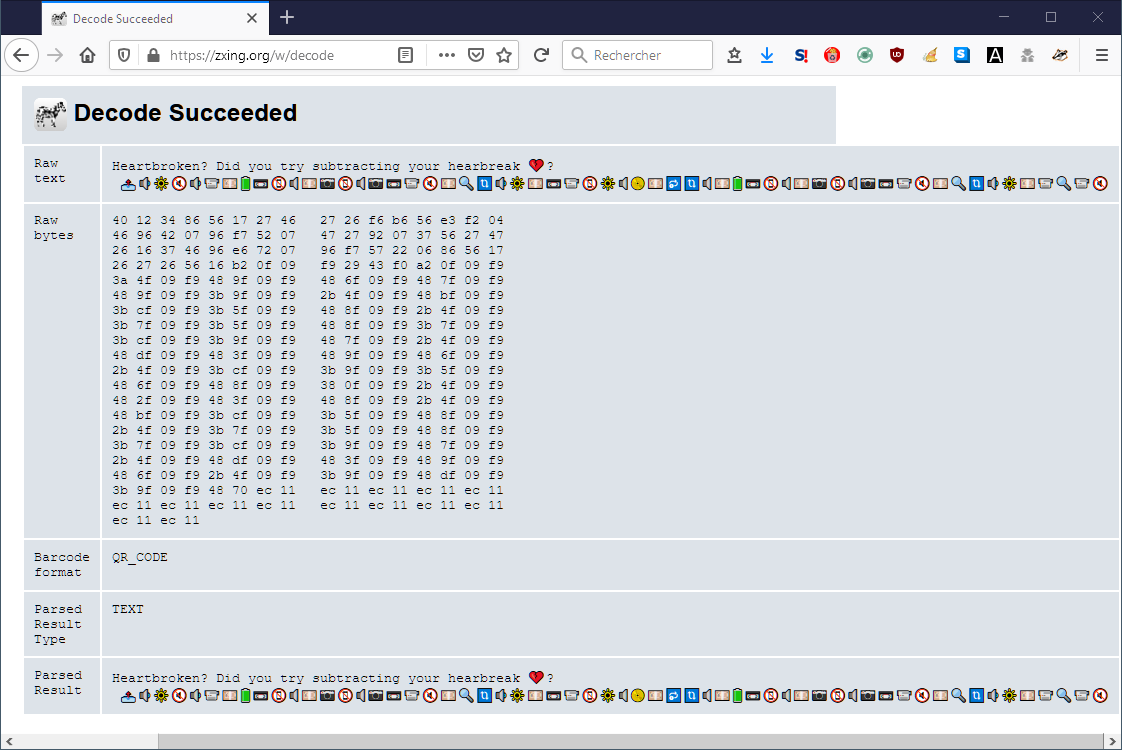
Encore un message avec des emojis, et en plus du binaire ? Je copie-colle la chaîne de 58 emojis de Firefox dans Notepad++, qui reconnaît l'UTF-8. De là, je la sors dans un fichier step5_string.bin. Quant au binaire, je le copie-colle de Firefox dans HxD, et je le loge dans un fichier step5_binary.bin.
Alors là, il est tard, et je vais faire un peu n'importe quoi. Pour commencer, je tente de soustraire le code UTF-8 du coeur brisé, f0 9f 92 94 du binaire - il s'agit classiquement de soustraire cette valeur des quatre premiers octets, puis des quatres suivants, etc. Ce qui ne donne rien d'intéressant. Ensuite, je tente de soustraire la chaîne du binaire. Ce qui ne donne rien de mieux. Enfin, je me demande si le binaire, ce n'est pas tout simplement ce que ZXing a trouvé dans le QR Code, et dont la traduction donne tout simplement la chaîne. Mais quel idiot !
Bref la seule opération possible, c'est de soustraire le coeur brisé de la chaîne. Je tente, mais cela ne donne rien d'intéressant. La soustraction évoquée est peut-être une opération particulière. Je génère quelques la fréquence des emojis dans la chaîne pour voir ce que cela m'inspire :
15 items f0:9f:93:a4 1 f0:9f:93:80 1 f0:9f:94:82 1 f0:9f:94:8b 2 f0:9f:94:8d 3 f0:9f:94:83 3 f0:9f:94:89 4 f0:9f:94:86 4 f0:9f:94:87 4 f0:9f:93:b7 4 f0:9f:93:bc 5 f0:9f:93:b5 5 f0:9f:93:b9 6 f0:9f:94:88 6 f0:9f:92:b4 9
Mouais... Cela étant, si la soustraction est bien une soustraction, cela peut tenir au type des opérandes. Des entiers de 32 octets et non des quadruplets d'octets par exemple ? Je tente cela, mais toujours rien, que ce soit en little endian ou en big endian.
Je vérifie que ZXing ne me sucre pas des informations dans ce qu'il me restitue. Pour cela, je décode moi-même le QR Code à l'aide de quelques lignes de Python mobilisant pyzbar. Je passe sur les difficultés pour l'installer sous une version de Kali obsolète, jusqu'à ce que je découvre que j'ai un problème de clé avec apt-get...
- from pyzbar.pyzbar import decode
- from PIL import Image
- image = Image.open ('step4.png')
- result = decode (image)
- print (result)
Ce qui donne :
[Decoded(data=b'Heartbroken? Did you try subtracting your hearbreak \xf0\x9f\x92\x94?\n \xf0\x9f\x93\xa4\xf0\x9f\x94\x89\xf0\x9f\x94\x86\xf0\x9f\x94\x87\xf0\x9f\x94\x89\xf0\x9f\x93\xb9\xf0\x9f\x92\xb4\xf0\x9f\x94\x8b\xf0\x9f\x93\xbc\xf0\x9f\x93\xb5\xf0\x9f\x94\x88\xf0\x9f\x92\xb4\xf0\x9f\x93\xb7\xf0\x9f\x93\xb5\xf0\x9f\x94\x88\xf0\x9f\x93\xb7\xf0\x9f\x93\xbc\xf0\x9f\x93\xb9\xf0\x9f\x94\x87\xf0\x9f\x92\xb4\xf0\x9f\x94\x8d\xf0\x9f\x94\x83\xf0\x9f\x94\x89\xf0\x9f\x94\x86\xf0\x9f\x92\xb4\xf0\x9f\x93\xbc\xf0\x9f\x93\xb9\xf0\x9f\x93\xb5\xf0\x9f\x94\x86\xf0\x9f\x94\x88\xf0\x9f\x93\x80\xf0\x9f\x92\xb4\xf0\x9f\x94\x82\xf0\x9f\x94\x83\xf0\x9f\x94\x88\xf0\x9f\x92\xb4\xf0\x9f\x94\x8b\xf0\x9f\x93\xbc\xf0\x9f\x93\xb5\xf0\x9f\x94\x88\xf0\x9f\x92\xb4\xf0\x9f\x93\xb7\xf0\x9f\x93\xb5\xf0\x9f\x94\x88\xf0\x9f\x93\xb7\xf0\x9f\x93\xbc\xf0\x9f\x93\xb9\xf0\x9f\x94\x87\xf0\x9f\x92\xb4\xf0\x9f\x94\x8d\xf0\x9f\x94\x83\xf0\x9f\x94\x89\xf0\x9f\x94\x86\xf0\x9f\x92\xb4\xf0\x9f\x93\xb9\xf0\x9f\x94\x8d\xf0\x9f\x93\xb9\xf0\x9f\x94\x87', type='QRCODE', rect=Rect(left=40, top=40, width=609, height=609), polygon=[Point(x=40, y=40), Point(x=42, y=649), Point(x=649, y=649), Point(x=649, y=42)])]
Tout est là. ZXing n'avait rien sucré.
Je tente de soustraire le coeur brisé de la chaîne en décalant ses octets de un, deux et trois octets. Toujours rien.
Changer d'unité ? Je me souviens vaguement que le code UTF-8 d'un caractère est une traduction pas triviale du nombre en hexadécimal préfixé de "U+". Lecture faite sur Wikipédia, c'est ce que l'on appelle le code point. Je récupère le code point de chaque caractère de la chaîne et du coeur brisé :
U+1F4E4 f0 9f 93 a4 OUTBOX TRAY U+1F4C0 f0 9f 93 80 DVD U+1F502 f0 9f 94 82 CLOCKWISE RIGHTWARDS AND LEFTWARDS OPEN CIRCLE ARROWS WITH CIRCLED ONE OVERLAY U+1F50B f0 9f 94 8b BATTERY U+1F50D f0 9f 94 8d LEFT-POINTING MAGNIFYING GLASS U+1F503 f0 9f 94 83 CLOCKWISE DOWNWARDS AND UPWARDS OPEN CIRCLE ARROWS U+1F509 f0 9f 94 89 SPEAKER WITH ONE SOUND WAVE U+1F506 f0 9f 94 86 HIGH BRIGHTNESS SYMBOL U+1F507 f0 9f 94 87 SPEAKER WITH CANCELLATION STROKE U+1F4F7 f0 9f 93 b7 CAMERA U+1F4F7 f0 9f 93 b7 CAMERA U+1F4FC f0 9f 93 bc VIDEOCASSETTE U+1F4F5 f0 9f 93 b5 NO MOBILE PHONES U+1F4F9 f0 9f 93 b9 VIDEO CAMERA U+1F508 f0 9f 94 88 SPEAKER U+1F4B4 f0 9f 92 b4 BANKNOTE WITH YEN SIGN U+1F494 f0 9f 92 94 BROKEN HEART
Le code point d'un caractère est une valeur entière comprise entre 000000 et 10FFFF. Elle est donnée en héxadécimal, préfixée par "U+". L'encodage en octets de cette valeur s'effectue sur un nombre variable d'octets, entre un et quatre selon la valeur :
| Début | Fin | Bits | Décodage |
| U+0000 | U+007F | 7 | 0------- |
| U+0080 | U+07FF | 11 | 110----- 10------ |
| U+0800 | U+FFFF | 15 | 1110---- 10------ 10------ |
| U+10000 | U+10FFFF | 21 | 11110--- 10------ 10------ 10------ |
Ainsi, pour retrouver la valeur entière pour un caractère codé sur 4 octets en UTF-8 :
11110aaa 10bbbbbb 10cccccc 10dddddd
...donne :
00000000 000aaabb bbbbcccc ccdddddd
Bref, je tente en Python :
- def getCodePoint (b):
- i = (b[0] & 0b111) << 18
- i |= (b[1] & 0b111111) << 12
- i |= (b[2] & 0b111111) << 6
- i |= b[3] & 0b111111
- return i
- file = open (f'{path}step5_string.bin', 'rb')
- data = file.read ()
- file.close ()
- key = b'\xf0\x9f\x92\x94'
- flag = ''
- for i in range (0, len (data), 4):
- flag += chr (getCodePoint(data[i: i + 4]) - getCodePoint(key))
- print (flag)
Ah ! J'obtiens une chaîne de caractères :
Pursue what catches your heart, not what catches your eyes
Super, mais ce n'est toujours pas le flag ! Cela fait 58 caractères. Ils font chier...
Alors, là, je vais passer les épisodes, mais je vais passer un temps fou, étalé sur plusieurs jours durant lesquels j'alterne entre plusieurs puzzles, à revenir sur l'image du chien tenant le coeur, me figurant que c'est donc une fausse piste que j'avais suivie et qu'elle me renvoie sur le puzzle pour tout reprendre en travaillant sur l'extraction de bits de certaines zones de l'image, comme la langue du chien que je trouve d'un rouge plus proche de celui des lunettes que celui du coeur.
Tout cela, pour qu'après des heures, je me dise qu'il est tout de même surprenant que dans un puzzle de ce type, je sois renvoyé au début après tant d'étapes. Ce que je cherche n'est-il pas dans la chaîne que j'ai trouvée ? J'en compte les mots pour réaliser que la phrase "Pursue what catches your heart" est composée de 30 caractères et de 5 mots, comme le flag qu'il faut trouver...
C'est ainsi que je tombe sur cette image :

Au suivant !